Using CellTypist for cell type classification
This notebook showcases the cell type classification for scRNA-seq query data by retrieving the most likely cell type labels from either the built-in CellTypist models or the user-trained custom models.
Only the main steps and key parameters are introduced in this notebook. Refer to detailed Usage if you want to learn more.
Install CellTypist
[1]:
!pip install celltypist
Collecting celltypist
Using cached celltypist-1.2.0-py3-none-any.whl (5.3 MB)
Requirement already satisfied: pandas>=1.0.5 in /opt/conda/lib/python3.8/site-packages (from celltypist) (1.2.3)
Requirement already satisfied: click>=7.1.2 in /opt/conda/lib/python3.8/site-packages (from celltypist) (7.1.2)
Requirement already satisfied: requests>=2.23.0 in /opt/conda/lib/python3.8/site-packages (from celltypist) (2.25.1)
Requirement already satisfied: leidenalg>=0.8.3 in /opt/conda/lib/python3.8/site-packages (from celltypist) (0.8.3)
Requirement already satisfied: scikit-learn>=0.24.1 in /opt/conda/lib/python3.8/site-packages (from celltypist) (0.24.1)
Requirement already satisfied: openpyxl>=3.0.4 in /opt/conda/lib/python3.8/site-packages (from celltypist) (3.0.7)
Requirement already satisfied: scanpy>=1.7.0 in /opt/conda/lib/python3.8/site-packages (from celltypist) (1.7.1)
Requirement already satisfied: numpy>=1.19.0 in /opt/conda/lib/python3.8/site-packages (from celltypist) (1.20.1)
Requirement already satisfied: et-xmlfile in /opt/conda/lib/python3.8/site-packages (from openpyxl>=3.0.4->celltypist) (1.0.1)
Requirement already satisfied: python-dateutil>=2.7.3 in /opt/conda/lib/python3.8/site-packages (from pandas>=1.0.5->celltypist) (2.8.1)
Requirement already satisfied: pytz>=2017.3 in /opt/conda/lib/python3.8/site-packages (from pandas>=1.0.5->celltypist) (2021.1)
Requirement already satisfied: six>=1.5 in /opt/conda/lib/python3.8/site-packages (from python-dateutil>=2.7.3->pandas>=1.0.5->celltypist) (1.15.0)
Requirement already satisfied: certifi>=2017.4.17 in /opt/conda/lib/python3.8/site-packages (from requests>=2.23.0->celltypist) (2020.12.5)
Requirement already satisfied: chardet<5,>=3.0.2 in /opt/conda/lib/python3.8/site-packages (from requests>=2.23.0->celltypist) (4.0.0)
Requirement already satisfied: idna<3,>=2.5 in /opt/conda/lib/python3.8/site-packages (from requests>=2.23.0->celltypist) (2.10)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in /opt/conda/lib/python3.8/site-packages (from requests>=2.23.0->celltypist) (1.26.3)
Requirement already satisfied: legacy-api-wrap in /opt/conda/lib/python3.8/site-packages (from scanpy>=1.7.0->celltypist) (0.0.0)
Requirement already satisfied: scipy>=1.4 in /opt/conda/lib/python3.8/site-packages (from scanpy>=1.7.0->celltypist) (1.6.1)
Requirement already satisfied: patsy in /opt/conda/lib/python3.8/site-packages (from scanpy>=1.7.0->celltypist) (0.5.1)
Requirement already satisfied: umap-learn>=0.3.10 in /opt/conda/lib/python3.8/site-packages (from scanpy>=1.7.0->celltypist) (0.4.6)
Requirement already satisfied: h5py>=2.10.0 in /opt/conda/lib/python3.8/site-packages (from scanpy>=1.7.0->celltypist) (3.1.0)
Requirement already satisfied: anndata>=0.7.4 in /opt/conda/lib/python3.8/site-packages (from scanpy>=1.7.0->celltypist) (0.7.5)
Requirement already satisfied: tqdm in /opt/conda/lib/python3.8/site-packages (from scanpy>=1.7.0->celltypist) (4.58.0)
Requirement already satisfied: natsort in /opt/conda/lib/python3.8/site-packages (from scanpy>=1.7.0->celltypist) (7.1.1)
Requirement already satisfied: matplotlib>=3.1.2 in /opt/conda/lib/python3.8/site-packages (from scanpy>=1.7.0->celltypist) (3.3.4)
Requirement already satisfied: networkx>=2.3 in /opt/conda/lib/python3.8/site-packages (from scanpy>=1.7.0->celltypist) (2.5)
Requirement already satisfied: tables in /opt/conda/lib/python3.8/site-packages (from scanpy>=1.7.0->celltypist) (3.6.1)
Requirement already satisfied: joblib in /opt/conda/lib/python3.8/site-packages (from scanpy>=1.7.0->celltypist) (1.0.1)
Requirement already satisfied: statsmodels>=0.10.0rc2 in /opt/conda/lib/python3.8/site-packages (from scanpy>=1.7.0->celltypist) (0.12.2)
Requirement already satisfied: sinfo in /opt/conda/lib/python3.8/site-packages (from scanpy>=1.7.0->celltypist) (0.3.1)
Requirement already satisfied: packaging in /opt/conda/lib/python3.8/site-packages (from scanpy>=1.7.0->celltypist) (20.9)
Requirement already satisfied: numba>=0.41.0 in /opt/conda/lib/python3.8/site-packages (from scanpy>=1.7.0->celltypist) (0.51.2)
Requirement already satisfied: seaborn in /opt/conda/lib/python3.8/site-packages (from scanpy>=1.7.0->celltypist) (0.11.1)
Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.3 in /opt/conda/lib/python3.8/site-packages (from matplotlib>=3.1.2->scanpy>=1.7.0->celltypist) (2.4.7)
Requirement already satisfied: pillow>=6.2.0 in /opt/conda/lib/python3.8/site-packages (from matplotlib>=3.1.2->scanpy>=1.7.0->celltypist) (8.1.2)
Requirement already satisfied: kiwisolver>=1.0.1 in /opt/conda/lib/python3.8/site-packages (from matplotlib>=3.1.2->scanpy>=1.7.0->celltypist) (1.3.1)
Requirement already satisfied: cycler>=0.10 in /opt/conda/lib/python3.8/site-packages (from matplotlib>=3.1.2->scanpy>=1.7.0->celltypist) (0.10.0)
Requirement already satisfied: decorator>=4.3.0 in /opt/conda/lib/python3.8/site-packages (from networkx>=2.3->scanpy>=1.7.0->celltypist) (4.4.2)
Requirement already satisfied: llvmlite<0.35,>=0.34.0.dev0 in /opt/conda/lib/python3.8/site-packages (from numba>=0.41.0->scanpy>=1.7.0->celltypist) (0.34.0)
Requirement already satisfied: setuptools in /opt/conda/lib/python3.8/site-packages (from numba>=0.41.0->scanpy>=1.7.0->celltypist) (49.6.0.post20210108)
Requirement already satisfied: threadpoolctl>=2.0.0 in /opt/conda/lib/python3.8/site-packages (from scikit-learn>=0.24.1->celltypist) (2.1.0)
Requirement already satisfied: get-version>=2.0.4 in /opt/conda/lib/python3.8/site-packages (from legacy-api-wrap->scanpy>=1.7.0->celltypist) (2.1)
Requirement already satisfied: stdlib-list in /opt/conda/lib/python3.8/site-packages (from sinfo->scanpy>=1.7.0->celltypist) (0.7.0)
Requirement already satisfied: numexpr>=2.6.2 in /opt/conda/lib/python3.8/site-packages (from tables->scanpy>=1.7.0->celltypist) (2.7.3)
Installing collected packages: celltypist
Successfully installed celltypist-1.2.0
[2]:
import scanpy as sc
[3]:
import celltypist
from celltypist import models
Download a scRNA-seq dataset of 2,000 immune cells
[4]:
adata_2000 = sc.read('celltypist_demo_folder/demo_2000_cells.h5ad', backup_url = 'https://celltypist.cog.sanger.ac.uk/Notebook_demo_data/demo_2000_cells.h5ad')
This dataset includes 2,000 cells and 18,950 genes collected from different studies, thereby showing the practical applicability of CellTypist.
[5]:
adata_2000.shape
[5]:
(2000, 18950)
The expression matrix (adata_2000.X) is pre-processed (and required) as log1p normalised expression to 10,000 counts per cell (this matrix can be alternatively stashed in .raw.X).
[6]:
adata_2000.X.expm1().sum(axis = 1)
[6]:
matrix([[10000. ],
[10000.002],
[10000. ],
...,
[10000. ],
[10000. ],
[10000. ]], dtype=float32)
Some pre-assigned cell type labels are also in the data, which will be compared to the predicted labels from CellTypist later.
[7]:
adata_2000.obs
[7]:
| cell_type | |
|---|---|
| cell1 | Plasma cells |
| cell2 | Plasma cells |
| cell3 | Plasma cells |
| cell4 | Plasma cells |
| cell5 | Plasma cells |
| ... | ... |
| cell1996 | Neutrophil-myeloid progenitor |
| cell1997 | Neutrophil-myeloid progenitor |
| cell1998 | Neutrophil-myeloid progenitor |
| cell1999 | Neutrophil-myeloid progenitor |
| cell2000 | Neutrophil-myeloid progenitor |
2000 rows × 1 columns
Assign cell type labels using a CellTypist built-in model
In this section, we show the procedure of transferring cell type labels from built-in models to the query dataset.
Download the latest CellTypist models.
[8]:
# Enabling `force_update = True` will overwrite existing (old) models.
models.download_models(force_update = True)
📜 Retrieving model list from server https://celltypist.cog.sanger.ac.uk/models/models.json
📚 Total models in list: 12
📂 Storing models in /home/jovyan/.celltypist/data/models
💾 Downloading model [1/12]: Immune_All_Low.pkl
💾 Downloading model [2/12]: Immune_All_High.pkl
💾 Downloading model [3/12]: Adult_Mouse_Gut.pkl
💾 Downloading model [4/12]: COVID19_Immune_Landscape.pkl
💾 Downloading model [5/12]: Cells_Fetal_Lung.pkl
💾 Downloading model [6/12]: Cells_Intestinal_Tract.pkl
💾 Downloading model [7/12]: Cells_Lung_Airway.pkl
💾 Downloading model [8/12]: Developing_Mouse_Brain.pkl
💾 Downloading model [9/12]: Healthy_COVID19_PBMC.pkl
💾 Downloading model [10/12]: Human_Lung_Atlas.pkl
💾 Downloading model [11/12]: Nuclei_Lung_Airway.pkl
💾 Downloading model [12/12]: Pan_Fetal_Human.pkl
All models are stored in models.models_path.
[9]:
models.models_path
[9]:
'/home/jovyan/.celltypist/data/models'
Get an overview of the models and what they represent.
[10]:
models.models_description()
👉 Detailed model information can be found at `https://www.celltypist.org/models`
[10]:
| model | description | |
|---|---|---|
| 0 | Immune_All_Low.pkl | immune sub-populations combined from 20 tissue... |
| 1 | Immune_All_High.pkl | immune populations combined from 20 tissues of... |
| 2 | Adult_Mouse_Gut.pkl | cell types in the adult mouse gut combined fro... |
| 3 | COVID19_Immune_Landscape.pkl | immune subtypes from lung and blood of COVID-1... |
| 4 | Cells_Fetal_Lung.pkl | cell types from human embryonic and fetal lungs |
| 5 | Cells_Intestinal_Tract.pkl | intestinal cells from fetal, pediatric and adu... |
| 6 | Cells_Lung_Airway.pkl | cell populations from scRNA-seq of five locati... |
| 7 | Developing_Mouse_Brain.pkl | cell types from the embryonic mouse brain betw... |
| 8 | Healthy_COVID19_PBMC.pkl | peripheral blood mononuclear cell types from h... |
| 9 | Human_Lung_Atlas.pkl | integrated Human Lung Cell Atlas (HLCA) combin... |
| 10 | Nuclei_Lung_Airway.pkl | cell populations from snRNA-seq of five locati... |
| 11 | Pan_Fetal_Human.pkl | stromal and immune populations from the human ... |
Choose the model you want to employ, for example, the model with all tissues combined containing low-hierarchy (high-resolution) immune cell types/subtypes.
[11]:
# Indeed, the `model` argument defaults to `Immune_All_Low.pkl`.
model = models.Model.load(model = 'Immune_All_Low.pkl')
Show the model meta information.
[12]:
model
[12]:
CellTypist model with 98 cell types and 6639 features
date: 2022-07-16 00:20:42.927778
details: immune sub-populations combined from 20 tissues of 18 studies
source: https://doi.org/10.1126/science.abl5197
version: v2
cell types: Age-associated B cells, Alveolar macrophages, ..., pDC precursor
features: A1BG, A2M, ..., ZYX
This model contains 98 cell states.
[13]:
model.cell_types
[13]:
array(['Age-associated B cells', 'Alveolar macrophages', 'B cells',
'CD16+ NK cells', 'CD16- NK cells', 'CD8a/a', 'CD8a/b(entry)',
'CMP', 'CRTAM+ gamma-delta T cells', 'Classical monocytes',
'Cycling B cells', 'Cycling DCs', 'Cycling NK cells',
'Cycling T cells', 'Cycling gamma-delta T cells',
'Cycling monocytes', 'DC', 'DC precursor', 'DC1', 'DC2', 'DC3',
'Double-negative thymocytes', 'Double-positive thymocytes', 'ELP',
'ETP', 'Early MK', 'Early erythroid', 'Early lymphoid/T lymphoid',
'Endothelial cells', 'Epithelial cells', 'Erythrocytes',
'Erythrophagocytic macrophages', 'Fibroblasts',
'Follicular B cells', 'Follicular helper T cells', 'GMP',
'Germinal center B cells', 'Granulocytes', 'HSC/MPP',
'Hofbauer cells', 'ILC', 'ILC precursor', 'ILC1', 'ILC2', 'ILC3',
'Intermediate macrophages', 'Intestinal macrophages',
'Kidney-resident macrophages', 'Kupffer cells',
'Large pre-B cells', 'Late erythroid', 'MAIT cells', 'MEMP', 'MNP',
'Macrophages', 'Mast cells', 'Megakaryocyte precursor',
'Megakaryocyte-erythroid-mast cell progenitor',
'Megakaryocytes/platelets', 'Memory B cells',
'Memory CD4+ cytotoxic T cells', 'Mid erythroid', 'Migratory DCs',
'Mono-mac', 'Monocyte precursor', 'Monocytes', 'Myelocytes',
'NK cells', 'NKT cells', 'Naive B cells',
'Neutrophil-myeloid progenitor', 'Neutrophils',
'Non-classical monocytes', 'Plasma cells', 'Plasmablasts',
'Pre-pro-B cells', 'Pro-B cells',
'Proliferative germinal center B cells', 'Promyelocytes',
'Regulatory T cells', 'Small pre-B cells', 'T(agonist)',
'Tcm/Naive cytotoxic T cells', 'Tcm/Naive helper T cells',
'Tem/Effector helper T cells', 'Tem/Effector helper T cells PD1+',
'Tem/Temra cytotoxic T cells', 'Tem/Trm cytotoxic T cells',
'Transitional B cells', 'Transitional DC', 'Transitional NK',
'Treg(diff)', 'Trm cytotoxic T cells', 'Type 1 helper T cells',
'Type 17 helper T cells', 'gamma-delta T cells', 'pDC',
'pDC precursor'], dtype=object)
Transfer cell type labels from this model to the query dataset using celltypist.annotate.
[14]:
# Not run; predict cell identities using this loaded model.
#predictions = celltypist.annotate(adata_2000, model = model, majority_voting = True)
# Alternatively, just specify the model name (recommended as this ensures the model is intact every time it is loaded).
predictions = celltypist.annotate(adata_2000, model = 'Immune_All_Low.pkl', majority_voting = True)
🔬 Input data has 2000 cells and 18950 genes
🔗 Matching reference genes in the model
🧬 5645 features used for prediction
⚖️ Scaling input data
🖋️ Predicting labels
✅ Prediction done!
👀 Can not detect a neighborhood graph, will construct one before the over-clustering
⛓️ Over-clustering input data with resolution set to 5
🗳️ Majority voting the predictions
✅ Majority voting done!
By default (majority_voting = False), CellTypist will infer the identity of each query cell independently. This leads to raw predicted cell type labels, and usually finishes within seconds or minutes depending on the size of the query data. You can also turn on the majority-voting classifier (majority_voting = True), which refines cell identities within local subclusters after an over-clustering approach at the cost of increased runtime.
The results include both predicted cell type labels (predicted_labels), over-clustering result (over_clustering), and predicted labels after majority voting in local subclusters (majority_voting). Note in the predicted_labels, each query cell gets its inferred label by choosing the most probable cell type among all possible cell types in the given model.
[15]:
predictions.predicted_labels
[15]:
| predicted_labels | over_clustering | majority_voting | |
|---|---|---|---|
| cell1 | Plasma cells | 44 | Plasma cells |
| cell2 | Plasma cells | 12 | Plasma cells |
| cell3 | Plasma cells | 36 | gamma-delta T cells |
| cell4 | Plasma cells | 1 | Plasma cells |
| cell5 | Plasma cells | 1 | Plasma cells |
| ... | ... | ... | ... |
| cell1996 | HSC/MPP | 9 | Neutrophil-myeloid progenitor |
| cell1997 | Neutrophil-myeloid progenitor | 27 | Neutrophil-myeloid progenitor |
| cell1998 | Neutrophil-myeloid progenitor | 28 | Neutrophil-myeloid progenitor |
| cell1999 | Neutrophil-myeloid progenitor | 27 | Neutrophil-myeloid progenitor |
| cell2000 | Neutrophil-myeloid progenitor | 9 | Neutrophil-myeloid progenitor |
2000 rows × 3 columns
Transform the prediction result into an AnnData.
[16]:
# Get an `AnnData` with predicted labels embedded into the cell metadata columns.
adata = predictions.to_adata()
Compared to adata_2000, the new adata has additional prediction information in adata.obs (predicted_labels, over_clustering, majority_voting and conf_score). Of note, all these columns can be prefixed with a specific string by setting prefix in to_adata.
[17]:
adata.obs
[17]:
| cell_type | predicted_labels | over_clustering | majority_voting | conf_score | |
|---|---|---|---|---|---|
| cell1 | Plasma cells | Plasma cells | 44 | Plasma cells | 0.999762 |
| cell2 | Plasma cells | Plasma cells | 12 | Plasma cells | 0.999926 |
| cell3 | Plasma cells | Plasma cells | 36 | gamma-delta T cells | 0.955991 |
| cell4 | Plasma cells | Plasma cells | 1 | Plasma cells | 0.999883 |
| cell5 | Plasma cells | Plasma cells | 1 | Plasma cells | 0.999890 |
| ... | ... | ... | ... | ... | ... |
| cell1996 | Neutrophil-myeloid progenitor | HSC/MPP | 9 | Neutrophil-myeloid progenitor | 0.152962 |
| cell1997 | Neutrophil-myeloid progenitor | Neutrophil-myeloid progenitor | 27 | Neutrophil-myeloid progenitor | 0.810408 |
| cell1998 | Neutrophil-myeloid progenitor | Neutrophil-myeloid progenitor | 28 | Neutrophil-myeloid progenitor | 0.961021 |
| cell1999 | Neutrophil-myeloid progenitor | Neutrophil-myeloid progenitor | 27 | Neutrophil-myeloid progenitor | 0.131777 |
| cell2000 | Neutrophil-myeloid progenitor | Neutrophil-myeloid progenitor | 9 | Neutrophil-myeloid progenitor | 0.985607 |
2000 rows × 5 columns
adata (If a pre-calculated neighborhood graph is already present in the AnnData, this graph construction step will be skipped).[18]:
# If the UMAP or any cell embeddings are already available in the `AnnData`, skip this command.
sc.tl.umap(adata)
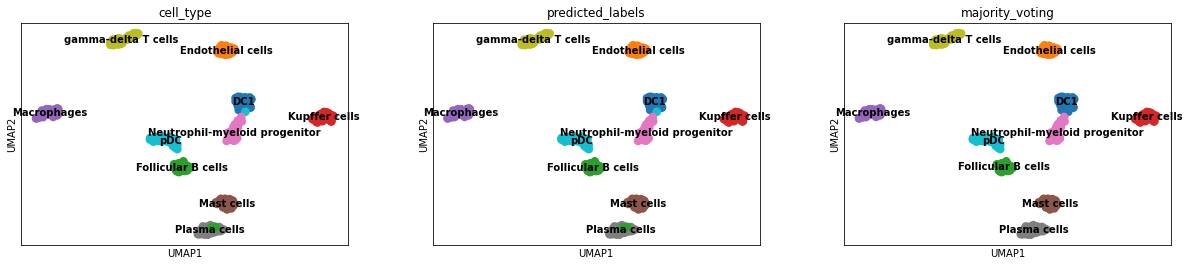
Visualise the prediction results.
[19]:
sc.pl.umap(adata, color = ['cell_type', 'predicted_labels', 'majority_voting'], legend_loc = 'on data')

Actually, you may not need to explicitly convert predictions output by celltypist.annotate into an AnnData as above. A more useful way is to use the visualisation function celltypist.dotplot, which quantitatively compares the CellTypist prediction result (e.g. majority_voting here) with the cell types pre-defined in the AnnData (here cell_type). You can also change the value of use_as_prediction
to predicted_labels to compare the raw prediction result with the pre-defined cell types.
[20]:
celltypist.dotplot(predictions, use_as_reference = 'cell_type', use_as_prediction = 'majority_voting')
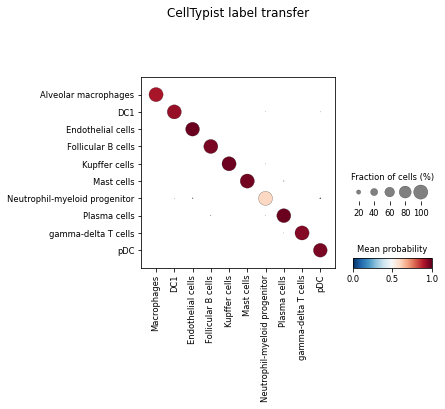
For each pre-defined cell type (each column from the dot plot), this plot shows how it can be ‘decomposed’ into different cell types predicted by CellTypist (rows).
Assign cell type labels using a custom model
In this section, we show the procedure of generating a custom model and transferring labels from the model to the query data.
Use previously downloaded dataset of 2,000 immune cells as the training set.
[21]:
adata_2000 = sc.read('celltypist_demo_folder/demo_2000_cells.h5ad', backup_url = 'https://celltypist.cog.sanger.ac.uk/Notebook_demo_data/demo_2000_cells.h5ad')
Download another scRNA-seq dataset of 400 immune cells as a query.
[22]:
adata_400 = sc.read('celltypist_demo_folder/demo_400_cells.h5ad', backup_url = 'https://celltypist.cog.sanger.ac.uk/Notebook_demo_data/demo_400_cells.h5ad')
Derive a custom model by training the data using the celltypist.train function.
[23]:
# The `cell_type` in `adata_2000.obs` will be used as cell type labels for training.
new_model = celltypist.train(adata_2000, labels = 'cell_type', n_jobs = 10, feature_selection = True)
🍳 Preparing data before training
✂️ 2749 non-expressed genes are filtered out
⚖️ Scaling input data
🏋️ Training data using SGD logistic regression
🔎 Selecting features
🧬 2607 features are selected
🏋️ Starting the second round of training
🏋️ Training data using logistic regression
✅ Model training done!
Refer to the function celltypist.train for what each parameter means, and to the usage for details of model training.
This custom model can be manipulated as with other CellTypist built-in models. First, save this model locally.
[24]:
# Save the model.
new_model.write('celltypist_demo_folder/model_from_immune2000.pkl')
You can load this model by models.Model.load.
[25]:
new_model = models.Model.load('celltypist_demo_folder/model_from_immune2000.pkl')
Next, we use this model to predict the query dataset of 400 immune cells.
[26]:
# Not run; predict the identity of each input cell with the new model.
#predictions = celltypist.annotate(adata_400, model = new_model, majority_voting = True)
# Alternatively, just specify the model path (recommended as this ensures the model is intact every time it is loaded).
predictions = celltypist.annotate(adata_400, model = 'celltypist_demo_folder/model_from_immune2000.pkl', majority_voting = True)
🔬 Input data has 400 cells and 18950 genes
🔗 Matching reference genes in the model
🧬 2607 features used for prediction
⚖️ Scaling input data
🖋️ Predicting labels
✅ Prediction done!
👀 Can not detect a neighborhood graph, will construct one before the over-clustering
⛓️ Over-clustering input data with resolution set to 5
🗳️ Majority voting the predictions
✅ Majority voting done!
[27]:
adata = predictions.to_adata()
[28]:
sc.tl.umap(adata)
[29]:
sc.pl.umap(adata, color = ['cell_type', 'predicted_labels', 'majority_voting'], legend_loc = 'on data')
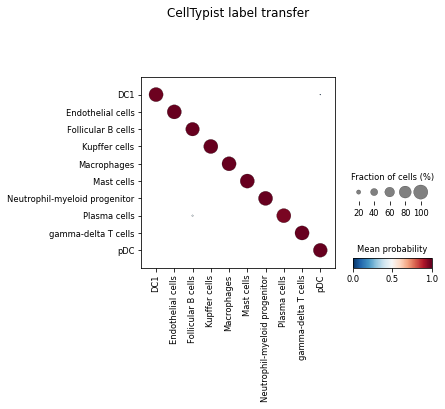
[30]:
celltypist.dotplot(predictions, use_as_reference = 'cell_type', use_as_prediction = 'majority_voting')
Examine expression of cell type-driving genes
Each model can be examined in terms of the driving genes for each cell type. Note these genes are only dependent on the model, say, the training dataset.
[31]:
# Any model can be inspected.
# Here we load the previously saved model trained from 2,000 immune cells.
model = models.Model.load(model = 'celltypist_demo_folder/model_from_immune2000.pkl')
[32]:
model.cell_types
[32]:
array(['DC1', 'Endothelial cells', 'Follicular B cells', 'Kupffer cells',
'Macrophages', 'Mast cells', 'Neutrophil-myeloid progenitor',
'Plasma cells', 'gamma-delta T cells', 'pDC'], dtype=object)
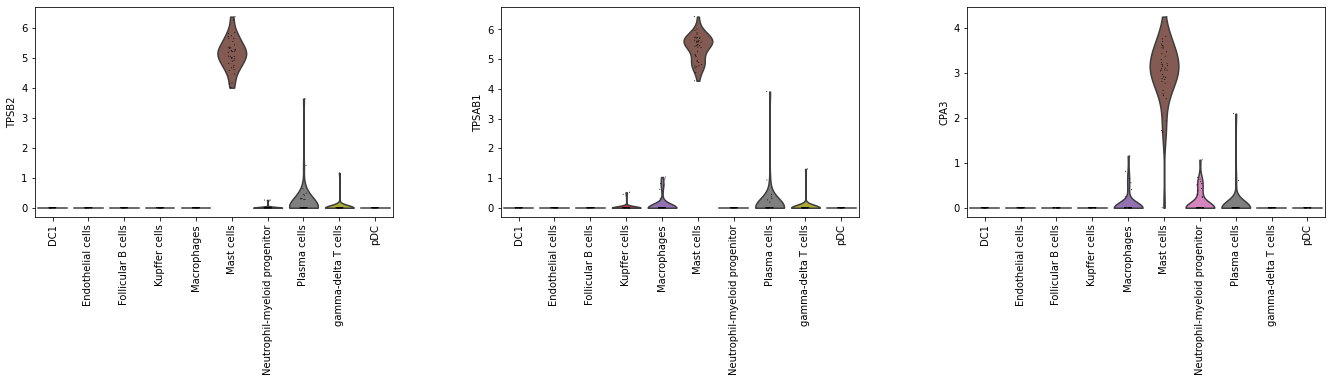
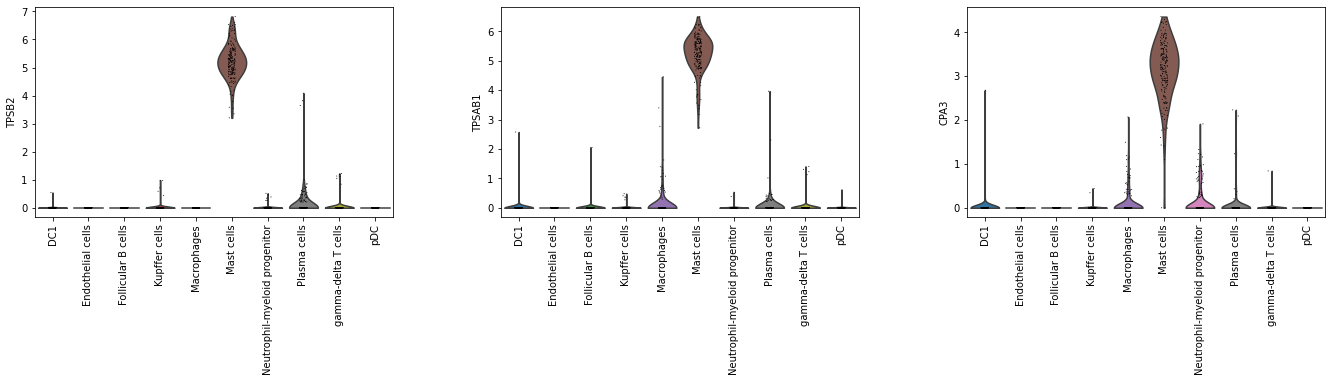
Extract the top three driving genes of Mast cells using the extract_top_markers method.
[33]:
top_3_genes = model.extract_top_markers("Mast cells", 3)
top_3_genes
[33]:
array(['TPSB2', 'TPSAB1', 'CPA3'], dtype=object)
[34]:
# Check expression of the three genes in the training set.
sc.pl.violin(adata_2000, top_3_genes, groupby = 'cell_type', rotation = 90)
[35]:
# Check expression of the three genes in the query set.
# Here we use `majority_voting` from CellTypist as the cell type labels for this dataset.
sc.pl.violin(adata_400, top_3_genes, groupby = 'majority_voting', rotation = 90)